The Import tool: create and update records
New records can be created and existing records updated with the Collections Import tool, which is accessed from the Main menu. Data, typically imported from a CSV file1, can be verified with a Test run option before the import is processed and records in your data sources![]() The management of a collection can involve a vast amount of information about objects / items / books, people and organizations, events, administration and more. This information is stored as records in data sources. Each data source stores a specific type of information: details about collection items, people, events, loans, and so on. are added or changed.
The management of a collection can involve a vast amount of information about objects / items / books, people and organizations, events, administration and more. This information is stored as records in data sources. Each data source stores a specific type of information: details about collection items, people, events, loans, and so on. are added or changed.
Before demonstrating how to use the Import tool, we describe how to construct a CSV import file. Note that building a CSV import file can require details about fields and the data they hold that is only available in Axiell Designer![]() A tool for designing, creating, customizing and managing Axiell Collections applications and databases, broadly speaking, the Axiell Collections Model Application. As well as managing databases, including user access and permissions, Designer is used for such tasks as translating field labels, tooltips, values in drop lists, etc..
A tool for designing, creating, customizing and managing Axiell Collections applications and databases, broadly speaking, the Axiell Collections Model Application. As well as managing databases, including user access and permissions, Designer is used for such tasks as translating field labels, tooltips, values in drop lists, etc..
How to build a CSV import file
Fields in Collections can have both:
- A data storage format: the format in which data is stored in the database.
-AND-
- A presentation format: the format in which data displays in the User Interface (UI).
When we build an import file, it is important that we enter data in the file in the format it is stored in the database rather than the format in which it displays in the UI.
When specifying the import data it is necessary to know certain properties of the import fields, such as:
- The field's data type.
This information, and more, is available in the Field properties box:
 How to access the Field properties box
How to access the Field properties boxThe Field properties box provides details about the properties of a field and the data it contains:

To display the Field properties box:
- Right-click a field in Record details View or Result set View when viewing or editing a record.
- Select Properties in the context menu that displays to display the Field properties box:

The Field properties box is described here.
-
Dates: the format of a date in the target field (the field that will be updated).
Each date field can have its own data and presentation formats. Typically, all dates are stored in the ISO date (
DateISO) format (yyyy-mm-dd), and while they can have a different presentation format in the UI (dd/mm/yyyy for instance), they usually do not. However, it is necessary to check in the Field properties box which data format a date field uses when importing dates:
When building your import data file, enter dates in the format in which they are stored in the target date field. Details about each Field (data) type and the required format can be found here.
- Decimal separator: the decimal separator (dot or comma) used in numerical fields.
Just as with dates, the decimal separator in numerical fields can be different when data is saved to the database and when presented in the UI and it is necessary to specify import data using the data storage decimal separator.
By default, numerical values are stored in the database with a dot as the decimal separator (e.g.
3.14159), but it is possible to specify a comma as the decimal separator (e.g.3,14159). This can only be checked in Axiell Designer A tool for designing, creating, customizing and managing Axiell Collections applications and databases, broadly speaking, the Axiell Collections Model Application. As well as managing databases, including user access and permissions, Designer is used for such tasks as translating field labels, tooltips, values in drop lists, etc..DetailsIn Axiell Designer:
- Select the (target) data source in which records will be updated by the import,
collect.infin this example. - Select the Advanced tab.
The Decimal separator drop list indicates which separator is used:

Details about decimal separators storage and presentation formats can be found in the Axiell Designer Help.
When performing the import you specify which decimal separator you have used in numerical fields in the import data file (details below): it is important to use the same decimal separator consistently.
- Select the (target) data source in which records will be updated by the import,
- Enumerative fields are read-only drop lists, such as:
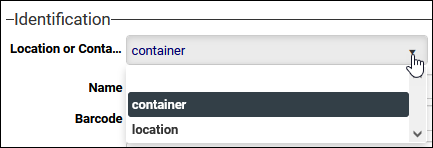
Again, the value stored in the database can be different from the value displayed in the UI, and it is necessary to specify the former. This can be checked in the UI or in Axiell Designer
A tool for designing, creating, customizing and managing Axiell Collections applications and databases, broadly speaking, the Axiell Collections Model Application. As well as managing databases, including user access and permissions, Designer is used for such tasks as translating field labels, tooltips, values in drop lists, etc..DetailsIn the UI it is necessary to check the values in an enumerative drop list one by one:
- With the value displaying in the field, right-click the field and select Properties in the context menu:
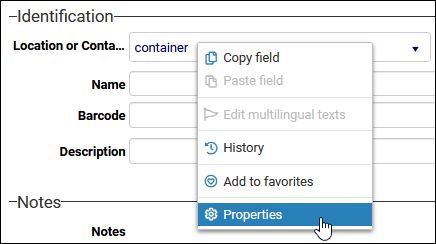
The database storage value is shown on the Data tab2:
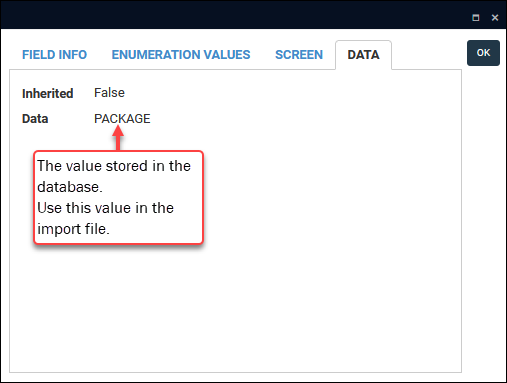
In Axiell Designer:
- Locate the Enumerative field in the target data source, current_location.package_location (2B) in this example.
- Select the Enumeration values tab:

- With the value displaying in the field, right-click the field and select Properties in the context menu:
Data is imported into Collections in a plain text file with a .csv extension; this can be created in an application such as Notepad or MS Excel:
- The header (first) row in the file is a comma separated list of field tags or system field names found in the data source The management of a collection can involve a vast amount of information about objects / items / books, people and organizations, events, administration and more. This information is stored as records in data sources. Each data source stores a specific type of information: details about collection items, people, events, loans, and so on. that will be updated (details about how to identify field tags and system field names can be found here).
Note: You can use a semicolon instead of a comma to separate fields and values, just be consistent and use one or the other.
Always use English system field names in the header row: if necessary, switch the Interface language to English before checking the system field name. Alternatively, use the field tag, which is the same in all languages.
The header row is not itself imported: it tells Collections which fields to update.
- Subsequent rows contain the comma separated values for each field listed in the header row.
Notes
|
Import |
Details |
|---|---|
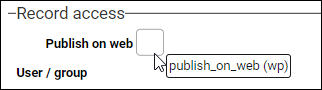
| Checkbox |
Here we see the Publish on web (publish_on_web (wp)) field on the Management details panel:
When a checkbox is not selected (it does not contain a tick), it is obviously empty and its value is NULL. When a checkbox is ticked, the value it holds is an To add a tick to a field with a checkbox when importing data, the value you import into the field is an |
|
When importing a new value into a Linked field
|
|
|
If you attempt to import data into a Merged-in field, you will receive an error similar to: Field ‘institution.code’ is a merge field that cannot process data. Data that displays in a Merged-in field is pulled dynamically from a linked record; it is important to understand that the data is not actually stored in the Merged-in field, it only displays in the field: the data is actually stored in the linked record. As such, data cannot be imported directly into a Merged-in field. Full details about Merged-in fields, and an explanation for the error message here. |
|
|
When you import data into a multilingual field, data is imported in the current data language. It is important to understand that it is only possible to import data in one language at a time. To import data in English and Arabic, for example, it is necessary to have two import files, one for each language. When importing the English data, ensure that the current data language is English; then switch the data language to Arabic and import the Arabic data. |
|
|
It is possible to import object / archive records with a new current or default location Where location names are unique it is possible to link object / archive records accurately by specifying a location name in location.default.name or current_location.name in the import file. A problem arises however when location names are not unique, something like Shelf 1 for instance. In versions of Collections prior to version 1.11, it is not possible to import non-unique location names and expect the link between an object / archive record and a location record to be correct: if there is more than one location called Shelf 1, which is the correct Shelf 1? Collections version 1.11 onwards provides a solution for this issue: Two conditions must be met to import locations with non-unique names:
When constructing the
Note: The full location context string is not actually stored in the location context field as the contents of such fields is generated dynamically. If an imported context string cannot be resolved because the relevant hierarchy does not exist in Locations and containers, an error will be generated and the record will not be imported / updated
|
|
|
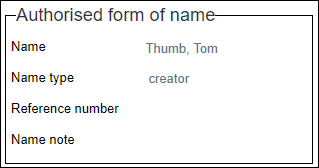
If a field is repeatable, multiple occurrences can be imported by adding a field name / tag for each occurrence. Tip: Each instance of the repeated field is treated in the same way as any other field in your import file, that is, separated by a comma or in a separate cell in the header row of an import file in MS Excel (see below).
For example: object_number;object_name;object_name FDJK001;bike;bicycle Note: Be sure that the field is repeatable. Field groups are respected during import, even if there is no value to import for an occurrence in the group. For example, this import data:
will result in the following record:
|




When you build an import file in MS Excel, be sure to save as:
CSV UTF-8 (Comma delimited) (*.csv)
Place each system field name or tag in a separate cell in the header row; values are placed in the corresponding cell in the subsequent rows, building a table with field names as column headers:

It is necessary to confirm which field separator character Excel is using. By default, Excel uses the separator character set in the Windows Control Panel (Clock and Region > Change date, time or number formats > Additional settings > List separator). A quick way to confirm which character has been used is to open your import .csv file in a text editor. When you perform the import it is necessary to specify this character in Settings (details here).
Auto-correction
Excel may auto-correct date formats, changing an ISO date to a European date for example. To set the required date format:
-
Right-click a column header and select Format Cells from the context menu.
-
In the Format Cells dialogue, set the required format for dates in this column:

To avoid Excel reformatting data in an existing .csv import file:
- Open a new blank workbook in Excel.
- On the Data tab of the Ribbon, select From Text/CSV and locate the
.csvfile and click Import.Excel opens the file in a preview window.
-
Make sure that the Delimiter option is set to the field separator used in the
.csvfile and that Data Type Detection is set to Do not detect data types to prevent automatic data formatting:
- Click Load.
The import data is loaded into Excel, and a header row is added with Column1 Column2, etc. We need to remove this;

- On the Table Design tab, remove the tick from the Header Row checkbox.
The row will be cleared but still present.
- Select the row and select Delete on the Home tab of the Ribbon.
- When you have finished making any other changes to the file, save as CSV UTF-8 (Comma delimited) (*.csv).
- Click OK if a message displays regarding support for workbooks containing multiple sheets.
When you build an import file in a text editor, be sure to save the file with a .csv extension.
You can use a semicolon or a comma to separate fields and values, just be consistent and use one or the other.
Tip: If you build the import file in Excel, field names and values are entered in cells and there is no need to key in the separator.
When you perform the import it is necessary to specify this character in Settings (details here).
It is important to type the separator character between field names / tags and between values, and to use double quotes where required:
Double quotes
Whenever the field separator character (comma or semicolon) appears in the import data, enclose the data in double quotes to prevent the character being interpreted as a separator. For example, if you are using a comma as the field separator, you would need to use double quotes here:
"Wood, Gerard"
Without the double quotes, the comma will be interpreted as a separator and Collections will attempt to split the value across two fields.
If any numerical values in your import data file include commas, and you use a comma as the field separator, you must enclose the entire numerical value in double quotes.
Tip: All values in the import file can be enclosed in double quotes whether the separator character is present or not.
If a value in your import data includes double quotes, these must be doubled and the entire value must also be enclosed in double quotes. For example, if you want to import the following value:
Annual reports energy management first "conceptual" draft
it would be formatted in the import file as:
"Annual reports energy management first ""conceptual"" draft"
In an import data file, this would appear as:
object_number,title,description_level,dating.date.start,creator
AK/OW/0211/b,"Annual reports energy management first ""conceptual"" draft",FILE,2011,St Johan District Board of Works
Tip: An advantage of building an import data file in MS Excel, is that Excel manages this in the background and you do not need to double up quotes.
Here we see an example .csv file containing five target fields and twelve records that will be imported into the Archives catalogue data source![]() The management of a collection can involve a vast amount of information about objects / items / books, people and organizations, events, administration and more. This information is stored as records in data sources. Each data source stores a specific type of information: details about collection items, people, events, loans, and so on.. In this case, a semicolon was used as the delimiter:
The management of a collection can involve a vast amount of information about objects / items / books, people and organizations, events, administration and more. This information is stored as records in data sources. Each data source stores a specific type of information: details about collection items, people, events, loans, and so on.. In this case, a semicolon was used as the delimiter:
object_number;title;description_level;dating.date.start;creator
AK/OW/0201;Annual reports energy management;FILE;2001;St Johan District Board of Works
AK/OW/0202;Annual reports energy management;FILE;2002;St Johan District Board of Works
AK/OW/0203;Annual reports energy management;FILE;2003;St Johan District Board of Works
AK/OW/0204;Annual reports energy management;FILE;2004;St Johan District Board of Works
AK/OW/0205;Annual reports energy management;FILE;2005;St Johan District Board of Works
AK/OW/0206;Annual reports energy management;FILE;2006;St Johan District Board of Works
AK/OW/0207;Annual reports energy management;FILE;2007;St Johan District Board of Works
AK/OW/0208;Annual reports energy management;FILE;2008;St Johan District Board of Works
AK/OW/0209;Annual reports energy management;FILE;2009;St Johan District Board of Works
AK/OW/0210;Annual reports energy management;FILE;2010;St Johan District Board of Works
AK/OW/0211;Annual reports energy management;FILE;2011;St Johan District Board of Works
AK/OW/0211/b;"Annual reports energy management first ""conceptual"" draft";FILE;2011;St Johan District Board of Works
Next we describe how to import your data with the Import tool.

